Tactical Robo-Dog
April 2026
Introduction
My ninth major course at USNA was EW442 (Ai & Data Science In Robotics). The course introduces artificial intelligence and data science for robotics and control engineering through real-world programming projects that cover web scraping, data processing, machine learning classifiers, neural networks, and reinforcement learning.
The culminating two-week final project was to design and implement an open-ended, self-directed artificial intelligence application utilizing the tools and techniques learned throughout the course.
I decided to train a reinforcement learning (RL) policy to teach a robot dog to navigate a tactical environment for Reconnaissance, Supply Delivery, Search & Rescue, etc. The goal is to train the policy to avoid obstacles, successfully reach a target, and evade enemy lines of sight.

Demo Video
Design Documentation
The project was conducted entirely within a simulated environment using NVIDIA's Isaac Lab and the RSL-RL library for Proximal Policy Optimization (PPO). The first step was to train a foundational locomotion policy to teach a Unitree Go2 robot dog to walk at commanded velocities.
Reinforcement Learning
To train the robot's autonomous behaviors, the project leverages Reinforcement Learning (RL), specifically utilizing the PPO algorithm and an Actor-Critic network.
- Reinforcement Learning (RL): RL is a machine learning paradigm where an "agent" (the robot) learns to make decisions by interacting with an environment. It learns through trial and error, receiving numerical rewards for desirable actions and penalties for undesirable ones, with the ultimate goal of maximizing its cumulative reward.
- Proximal Policy Optimization (PPO): PPO is a highly stable and efficient on-policy RL algorithm widely used in robotics. Its defining feature is that it limits how much the policy can change during a single training update. This prevents the model from making drastic, destructive updates that could cause the robot to suddenly "forget" how to walk.
- Actor-Critic Network: This architecture splits the learning process into two distinct neural networks.
- The Actor is the policy network; it observes the current state of the environment (e.g., joint positions, terrain) and decides which action to take (e.g., motor torques).
- The Critic evaluates the action taken by the Actor by predicting the expected future reward. The Critic's feedback guides the Actor, helping it improve its decision-making over time.
Locomotion Policy
The walking policy dictates how the Unitree Go2 physically moves through the environment. Rather than explicitly programming how the robot should move its legs, the policy is shaped by a carefully tuned reward function. The weights of this function are balanced to achieve three main objectives: matching commanded speeds, maintaining physical stability, and ensuring energy-efficient, safe movements.
Movement and Tracking Rewards (Incentives) These positive rewards encourage the robot to actively move and follow velocity commands.
- Linear Velocity Reward (1.5): The heaviest positive weight, ensuring the robot accurately matches the target forward, backward, or lateral speed.
- Angular Velocity Reward (0.75): Encourages the robot to turn at the correct commanded yaw rate.
- Feet Airtime Reward (0.25): Incentivizes the robot to lift its feet off the ground for sustained periods, which forces it to step naturally rather than dragging its hooves.
Stability Penalties (Posture Control) These penalties prevent the robot from losing its balance or walking with a sloppy gait.
- Linear Z-Velocity Penalty (-2.0): The heaviest penalty, heavily discouraging vertical bouncing to ensure a smooth, level walking motion.
- Base Height Penalty (-1.0): Punishes the robot if its main body deviates from the optimal standing height, preventing it from crouching too low or standing too tall.
- Base Angular XY-Velocity Penalty (-0.05): Discourages unnecessary pitch and roll of the torso, keeping the robot's back flat and stable while walking.
Safety and Efficiency Penalties (Sim-to-Real Transferability) These parameters ensure the movements learned in simulation are safe and physically viable for the real-world hardware.
- Undesired Contact Penalty (-1.0): Heavily penalizes the robot if any body part other than its feet (such as its knees or torso) touches the ground, which teaches it to avoid falling or scraping obstacles.
- Action Rate Penalty (-0.01): Discourages rapid, jerky changes in motor commands, promoting smooth transitions between movements.
- Torque/Energy Penalty (-0.0002): A small but vital penalty that encourages energy efficiency by minimizing the overall torque output of the motors.
- Joint Acceleration/Velocity Penalty (-2.5e-7): Prevents the joints from moving at physically impossible or dangerous speeds, protecting the hardware from wear and tear.

After 1,500 training iterations, the robot successfully learned to walk at commanded velocities while maintaining stability and avoiding unsafe behaviors. The trained policy can be deployed on the physical Unitree Go2 robot dog, enabling it to navigate real-world environments for various tactical applications.
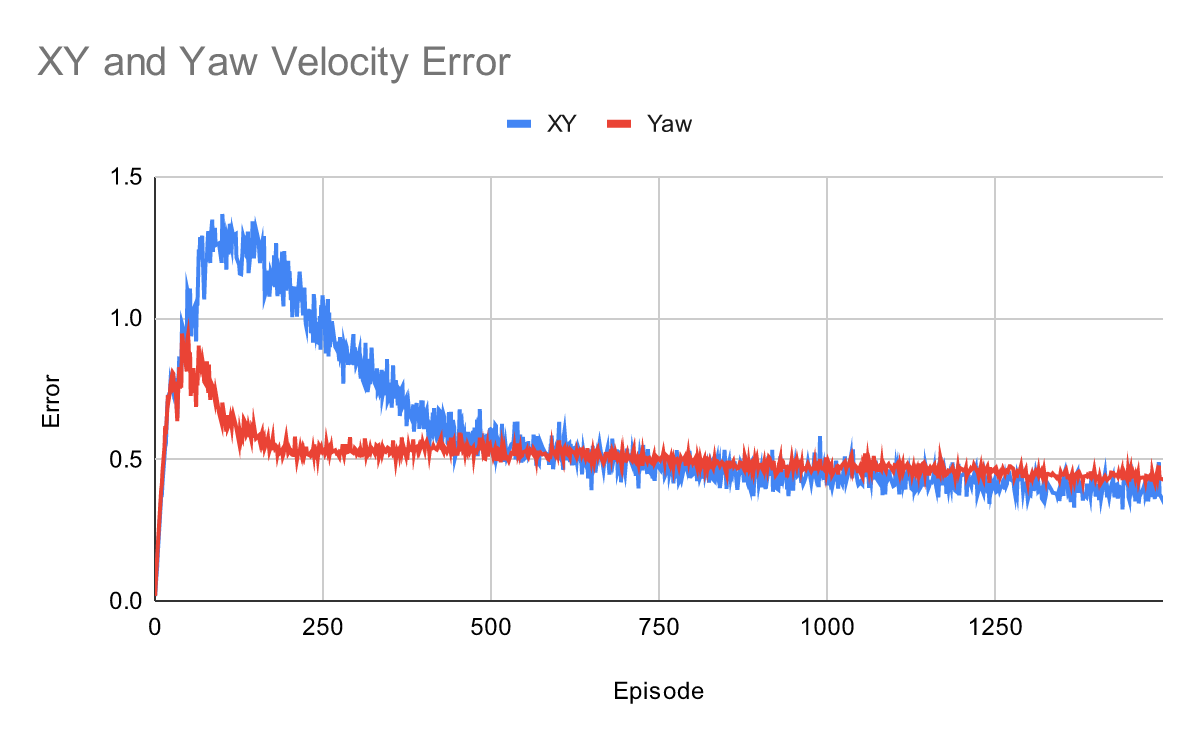
Base contact termination is when the robot's main body (base) makes contact with the ground, which is a critical failure state in quadruped locomotion. In the training process, if the robot's base touches the ground, it indicates a fall or loss of balance, which is highly undesirable. To prevent this, the training environment is configured to terminate the episode immediately when base contact occurs. This means that if the robot falls over during training, it receives a significant penalty and the episode ends, reinforcing the importance of maintaining balance and stability throughout the learning process.
Tactical Navigation
To achieve the complex behavior of navigating to a target while avoiding obstacles and staying in cover, the project uses a hierarchical policy structure and a custom, highly randomized training environment. The training was conducted at scale, running 4,096 environment instances in parallel for 1,500 iterations.
Hierarchical Policy Execution (Policy over Policy)
Instead of training a single neural network to control the robot's joint motors directly from high-level spatial observations, the navigation agent acts as a high-level manager.
- High-Level Tactical Policy: This policy processes tactical observations (the relative vector to the goal and LiDAR distance measurements) and outputs commanded velocities: forward speed, lateral speed, and yaw rate.
- Low-Level Walking Policy: The previously trained foundational walking policy receives these velocity commands and translates them into the 12 specific joint positions required to move the robot.
- Decimation: The high-level navigation policy operates with a decimation factor of 4, meaning it runs four times slower than the low-level walking policy. This allows the navigation agent to focus on macro-level pathfinding while the walking policy seamlessly handles the high-frequency micro-adjustments needed for balance.
Environment Construction
The simulation environment is dynamically constructed to force the agent to learn robust tactical behaviors:
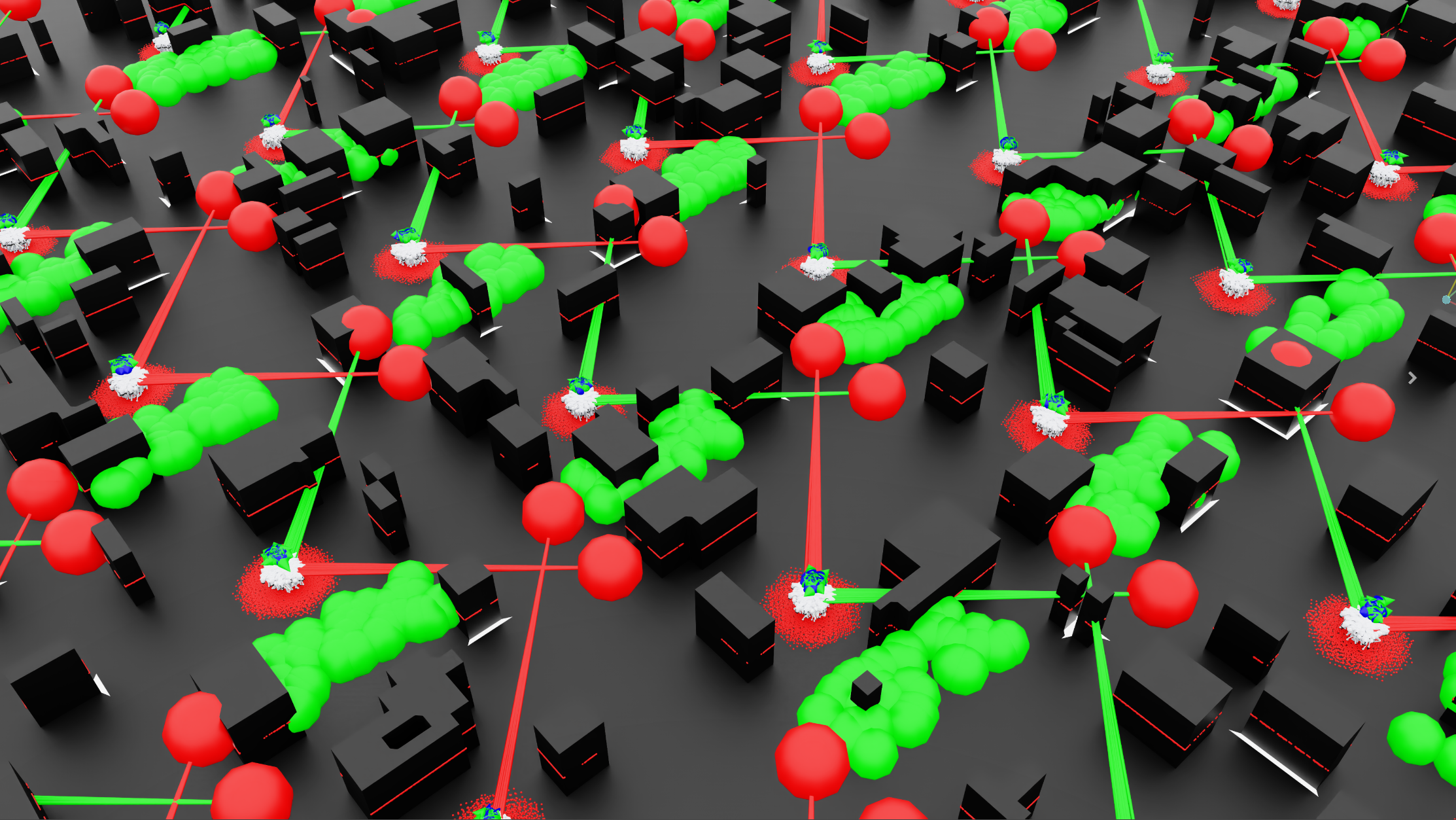
- Procedural Cover Generation: Each of the 4,096 environments features an 8x8 meter terrain patch populated with randomly generated urban cover. Up to 8 discrete obstacles are spawned with varying widths and a fixed height of 1.5 meters—tall enough to completely block line of sight.

- Static Enemies (Threats): Two static enemies are positioned at fixed elevated coordinates (
[5.0, 5.0, 1.0]and[-5.0, 5.0, 1.0]) relative to the environment origin. - Randomized Goals: At the start of every episode, a single target goal location is randomly generated within the reachable area of the local terrain patch.
Task Objectives and Reward Shaping
The tactical navigation policy learns through a weighted combination of three primary reward/penalty functions:
1. Target Location Reaching (3.4) The heaviest positive reward incentivizes the robot to find and reach the randomized goal location.
- The reward function calculates the robot's progress vector towards the goal.
- It includes an exponential shaping term that increases steadily as the robot gets closer to the target.
- A massive flat bonus is granted the moment the robot successfully enters the goal radius (0.8 meters), which strongly encourages episode completion.
2. Obstacle Avoidance (1.5) To prevent the robot from colliding with the randomly generated urban cover, the environment uses simulated 360-degree LiDAR.
- The system evaluates the minimum distance to any wall or obstacle.
- If the robot maintains a safe clearance distance (greater than 0.6 meters), it receives a continuous clearance bonus.
- If the robot breaches this safety threshold and gets too close to an obstacle, a heavy exponential penalty is applied to force it to path around the structure.
3. Enemy Line of Sight Avoidance (-0.6) The core tactical element of the project relies on teaching the robot to utilize the physical obstacles as cover against the two static enemies.
- The environment utilizes a custom physics raycasting utility that draws an line between each threat and the robot.
- If this ray hits an environment mesh (an obstacle) before hitting the robot, the robot is considered "blocked" and safe.
- If the raycast has a clear path to the robot, the robot is "exposed." For every simulation step the robot spends exposed, a continuous penalty is applied, scaled by how many threats can currently see it. This teaches the policy to naturally prefer routes that hug walls and break lines of sight.
Results and Evaluation
To validate the effectiveness of the reinforcement learning approach, the Custom RL Policy's performance was evaluated against a classical navigation controller and analyzed across its training lifespan.
Baseline Comparison: Artificial Potential Fields (APF)
To rigorously test the RL policy's tactical awareness, it was compared against a traditional, non-learning Artificial Potential Field (APF) baseline controller.
An Artificial Potential Field is a classical robotics navigation algorithm that treats the robot as a particle moving through a field of forces. The goal position generates an "attractive" force pulling the robot toward it, while obstacles generate "repulsive" forces pushing the robot away.
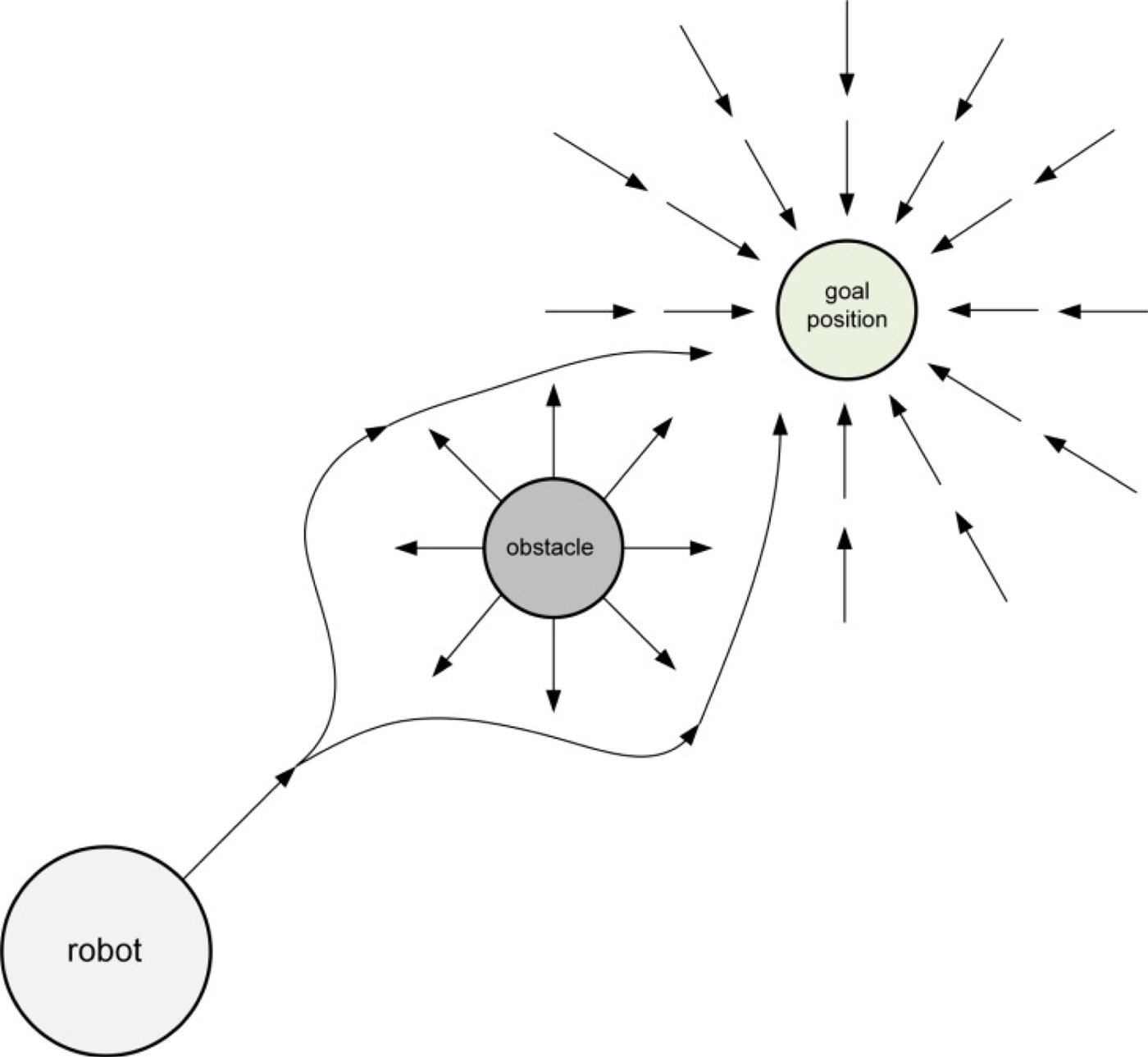
In this project, the APF baseline calculates an attractive vector toward the goal in the robot's body frame and applies repulsive vectors based on proximity measurements from the simulated LiDAR. The resultant vector dictates the robot's desired heading and speed.
This method was chosen as a baseline for two key reasons:
- It is a highly reliable, standard method for basic, obstacle-free point-to-point navigation.
- The APF controller intentionally does not utilize or process enemy line-of-sight (LOS) states.
Because the APF baseline only cares about spatial efficiency and obstacle avoidance, it serves as a perfect control group to prove that the RL policy has actively learned stealth and cover-seeking behaviors, rather than just stumbling into cover by chance.
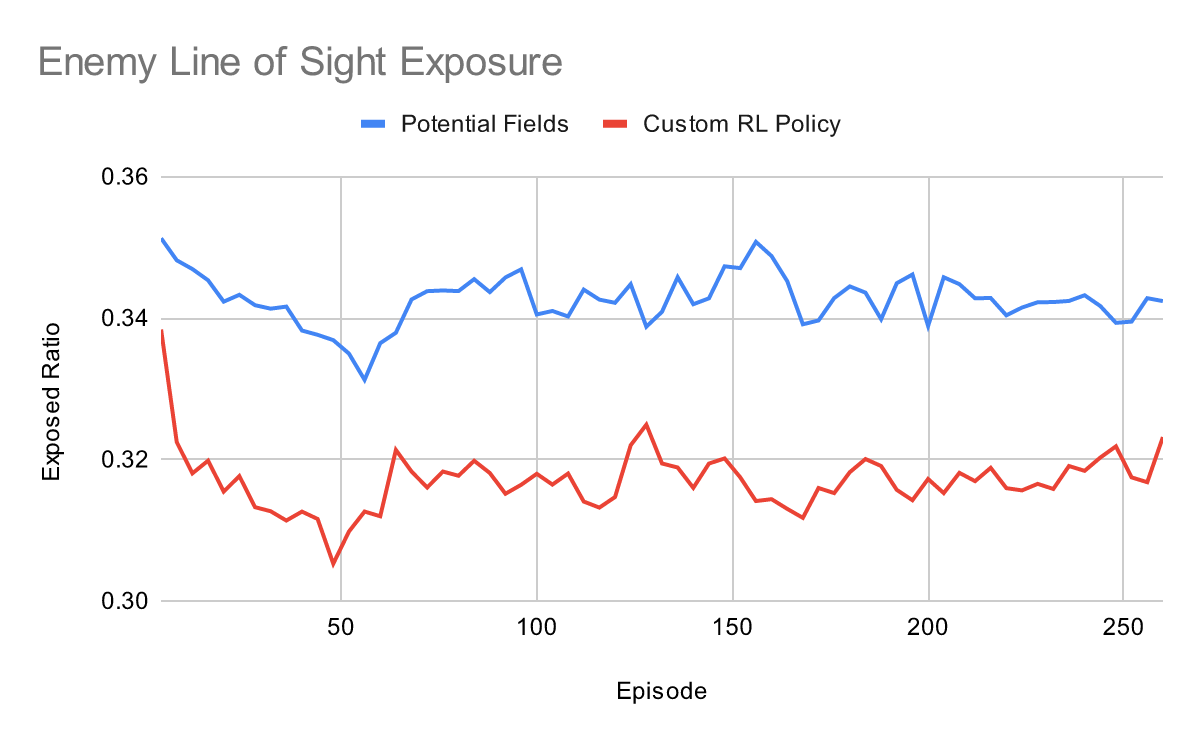
Tactical Stealth Performance (Line of Sight Exposure)
The primary metric for tactical success is the ratio of time the robot spends exposed to enemy sightlines while navigating to the objective.
As shown in the Enemy Line of Sight Exposure plot, the Custom RL Policy outperforms the Potential Fields baseline. The APF baseline consistently maintains an exposure ratio between 0.34 and 0.35, as it takes the most direct, obstacle-free path regardless of enemy positioning. Conversely, the Custom RL Policy consistently maintains a lower exposure ratio (~0.31 to 0.32). This measurable reduction confirms that the negative reward shaping for LOS exposure successfully taught the agent to deviate from the shortest path in order to actively utilize urban obstacles as cover.
Policy Convergence and Termination States
The Episode Termination plot visualizes how the RL policy learned to balance its competing objectives over the course of 1,500 training episodes. Evaluating the specific reasons episodes ended provides insight into the policy's stability and efficiency:
- Goal Reached (Blue): This tracks the policy's success rate. During early exploration, success is low, but the policy rapidly learns, with the success rate climbing and eventually stabilizing above 70% (a ratio of >0.7). This indicates strong proficiency in finding the randomized targets.
- Timeout (Red): This tracks episodes where the robot failed to reach the goal within the time limit (60 sec). Timeouts peak early in training while the robot is still figuring out how to move efficiently or gets stuck behind cover. As the policy matures, the timeout rate drops and stabilizes around 20%, showing improved pathing efficiency.
- Base Contact (Yellow): This tracks catastrophic physical failures where the robot's torso hits the ground (e.g., tripping, falling, or crashing into walls). This failure rate stays remarkably low throughout training, peaking near 15% before settling comfortably below 10%. This demonstrates that the hierarchical structure works: the high-level tactical manager is issuing safe, smooth commands that the low-level walking policy can execute without losing balance.